|
Sangeek Hyun I am a Ph.D. candidate in the Visual Computing Lab (VCLab) at Sungkyunkwan University, supervised by Prof. Jae-Pil Heo. I received my Master's and Bachelor's degrees from Sungkyunkwan University. My research interests include various tasks in machine learning and computer vision, with a particular focus on generative models and video understanding. Email / Google Scholar / Github / LinkedIn / CV |

|
ResearchRecently my interest has been in 3D generative models using Generative Adversarial Networks and gaussian splatting. I am also interested in various generation tasks using large-scale diffusion models. |

|
Scalable GANs with Transformers
Sangeek Hyun, MinKyu Lee, Jae-Pil Heo Arxiv, 2025 project page / code (coming soon) / arXiv Pure Transformer GANs can be scaled up and beats diffusion/flow models on an one-step conditional generation on ImageNet-256 only within 40 epochs. |
|
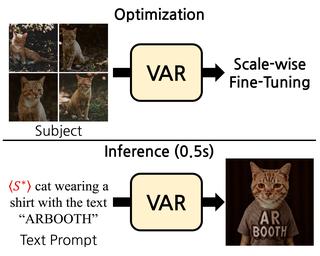
Fine-Tuning Visual Autoregressive Models for Subject-Driven Generation
Jiwoo Chung, Sangeek Hyun, Hyunjun Kim, Eunseo Koh, MinKyu Lee, Jae-Pil Heo ICCV, 2025 project page / code / arXiv This paper introduces a fast and effective VAR-based method for subject-driven image generation, using selective and scale-wise weighted tuning to overcome fine-tuning challenges and outperform diffusion models. |

|
AESOP: Auto-Encoded Supervision for Perceptual Image Super-Resolution
MinKyu Lee, Sangeek Hyun, Woojin Jun, Jae-Pil Heo CVPR, 2025 code / arXiv This paper proposes AESOP, a simple yet effective loss that replaces pixel-wise Lp loss with a distance in the autoencoder output space, enabling better reconstruction in perceptual super-resolution without sacrificing visual quality. |

|
GSGAN: Adversarial Learning for Hierarchical Generation of 3D Gaussian Splats
Sangeek Hyun, Jae-Pil Heo NeurIPS, 2024 Winner of Qualcomm Innovation Fellowship Korea 2024 (QIFK 2024) project page / code / arXiv First 3D GANs utilize gaussian splatting without any structural priors, achieving faster rendering speed at high-resolution data compared to NeRFs. |
|
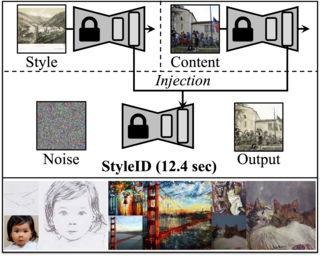
Style Injection in Diffusion: A Training-free Approach for Adapting Large-scale Diffusion Models for Style Transfer
Jiwoo Chung*, Sangeek Hyun*, Jae-Pil Heo (*: Equal contribution) CVPR, 2024 (Highlight) project page / code / paper / arXiv Training-free style transfer utilizes large-scale diffusion models by manipulating the attention features. |
|
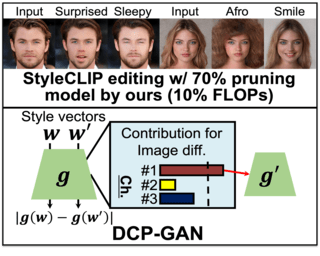
Diversity-aware Channel Pruning for StyleGAN Compression
Jiwoo Chung, Sangeek Hyun, Sang-Heon Shim, Jae-Pil Heo CVPR, 2024 code / paper / arXiv GAN compression technique by pruning the diversity-aware channels in StyleGAN architecture. |
|
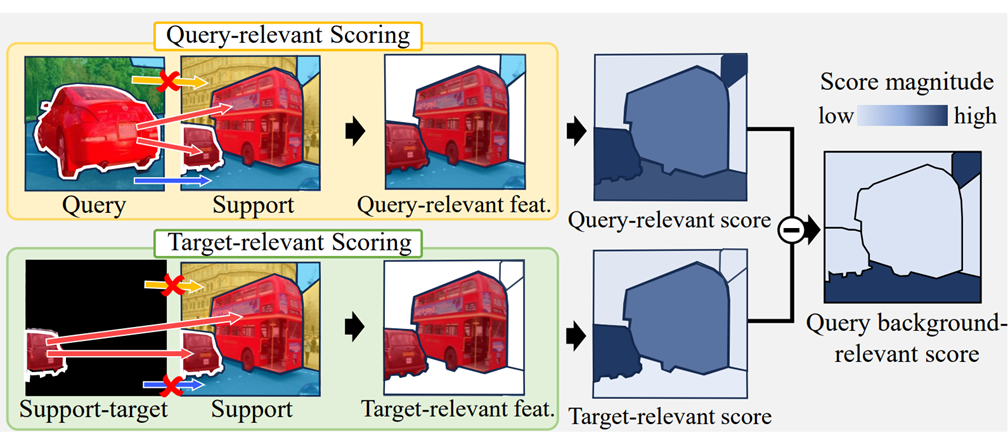
Task-disruptive Background Suppression for Few-Shot Segmentation
Suho Park, SuBeen Lee, Sangeek Hyun, Hyun Seok Seong, Jae-Pil Heo AAAI, 2024 code / paper / arXiv Task-disruptive Background Suppression mitigates the negative impact of dissimilar or target-similar support backgrounds, improving the accuracy of segmenting novel target objects in query images. |
|
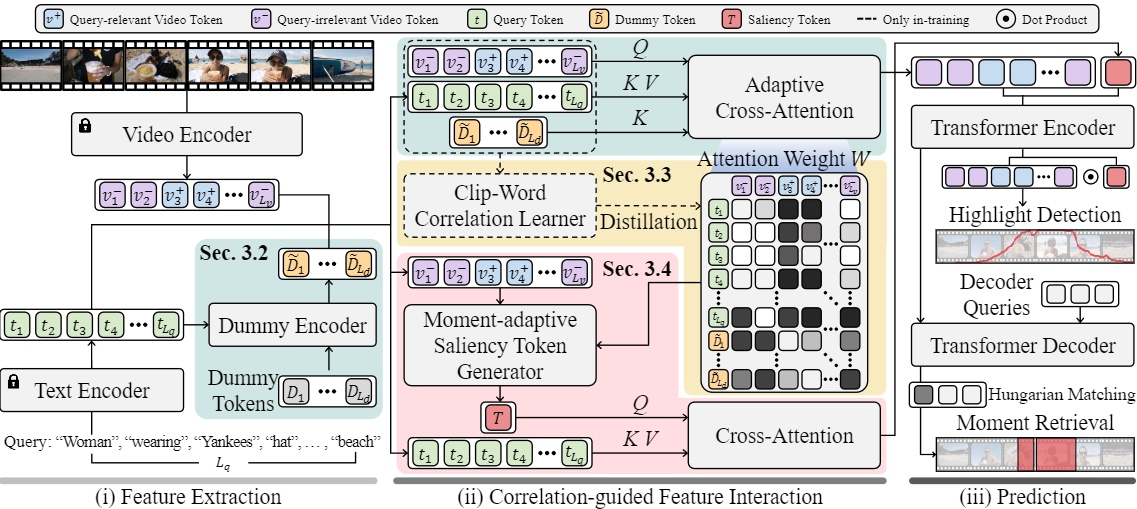
Correlation-guided Query-Dependency Calibration in Video Representation Learning for Temporal Grounding
WonJun Moon, Sangeek Hyun, SuBeen Lee, Jae-Pil Heo Arxiv, 2023 code / arXiv CG-DETR improves temporal grounding by using adaptive cross-attention and clip-word correlation to accurately identify video highlights corresponding to textual descriptions. |
|
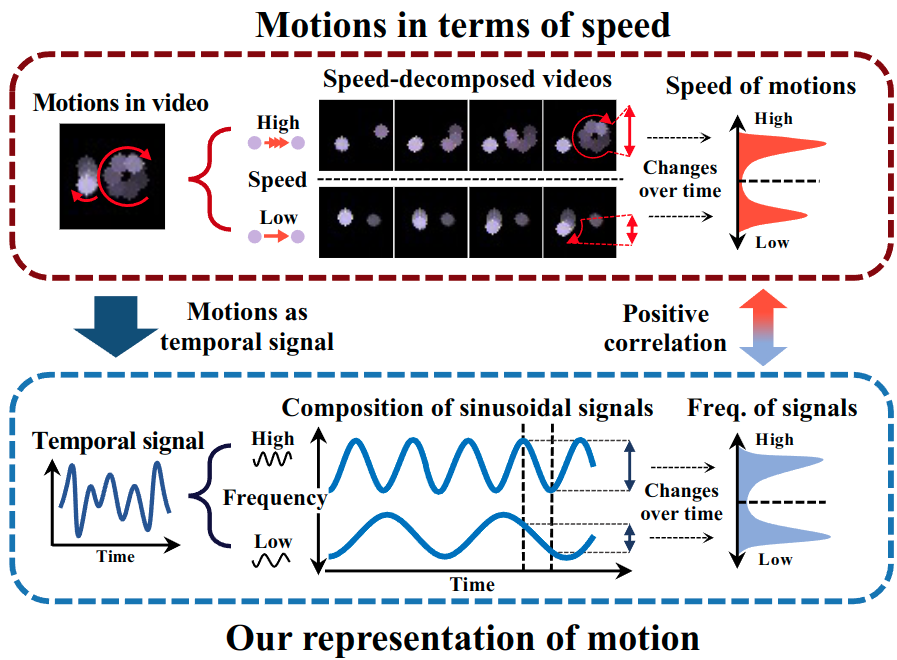
Frequency-based motion representation for video generative adversarial networks
Sangeek Hyun, Jaihyun Lew, Jiwoo Chung, Euiyeon Kim, Jae-Pil Heo TIP, 2023 project page / code / paper Propose a frequency-based motion representation for video GANs, enabling speed-aware motion generation, which improves video quality and editing capability. |
|
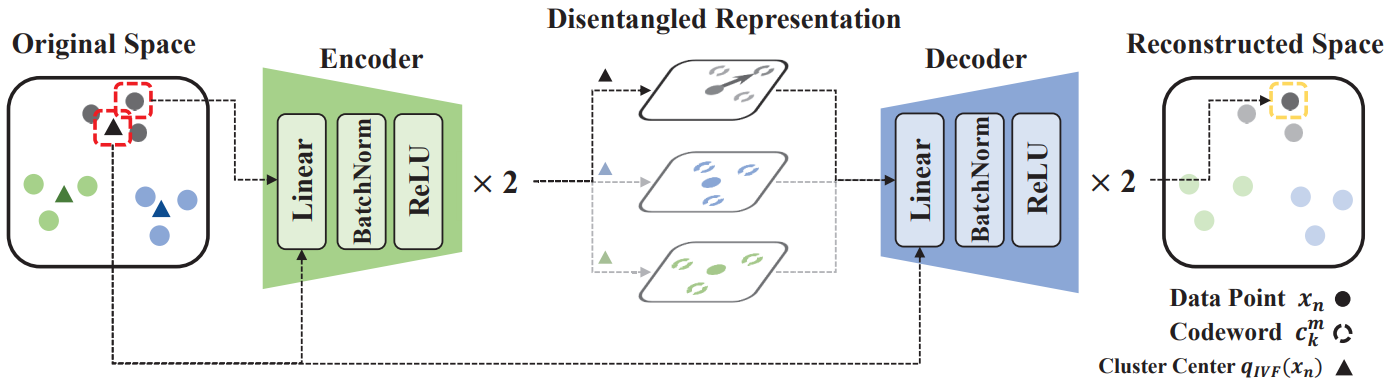
Disentangled Representation Learning for Unsupervised Neural Quantization
Haechan Noh, Sangeek Hyun, Woojin Jeong, Hanshin Lim, Jae-Pil Heo CVPR, 2023 paper Disentangled representation learning for unsupervised neural quantization addresses deep learning quantizers' limitations in leveraging residual vector space, enhancing search efficiency and quality. |
|
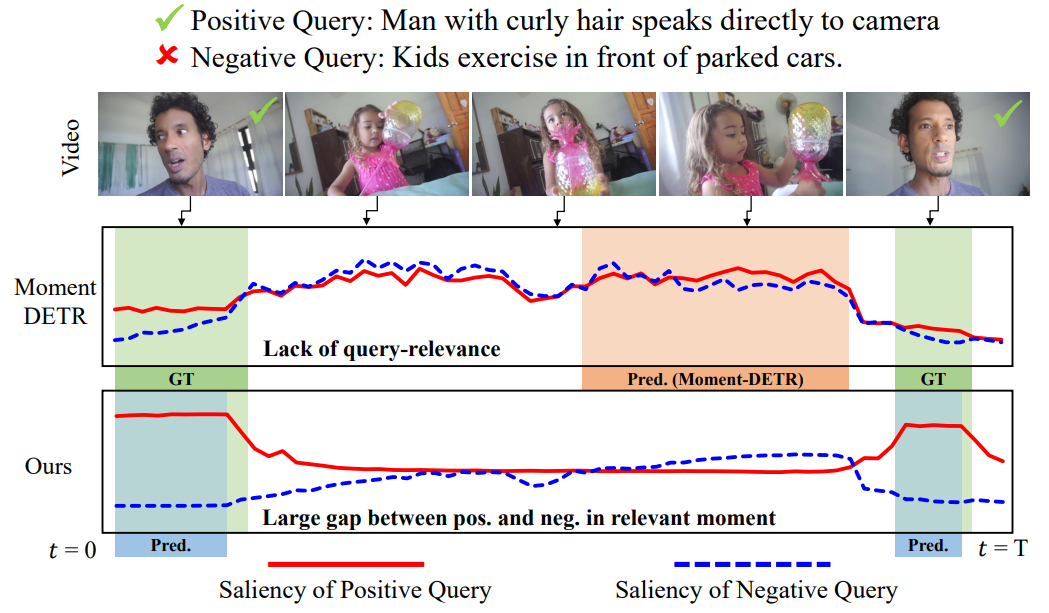
Query-dependent video representation for moment retrieval and highlight detection
WonJun Moon*, Sangeek Hyun*, SangUk Park, Dongchan Park, Jae-Pil Heo (*: Equal contribution) CVPR, 2023 project page / code / paper / arXiv Query-Dependent DETR improves video moment retrieval and highlight detection by enhancing query-video relevance and using negative pairs to refine saliency prediction. |
|
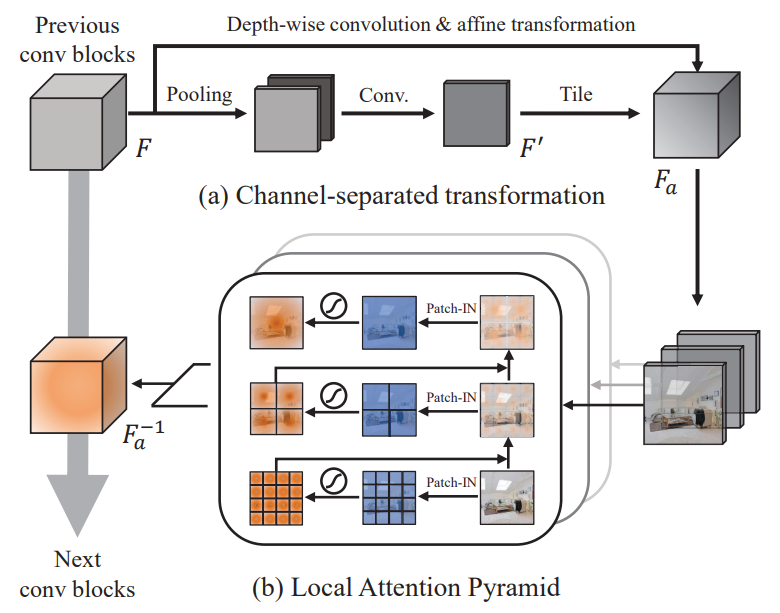
Local attention pyramid for scene image generation
Sang-Heon Shim, Sangeek Hyun, DaeHyun Bae, Jae-Pil Heo CVPR, 2022 paper The Local Attention Pyramid (LAP) module addresses class-wise visual quality imbalance in GAN-generated scene images by enhancing attention to diverse object classes, particularly small and less frequent ones. |
|
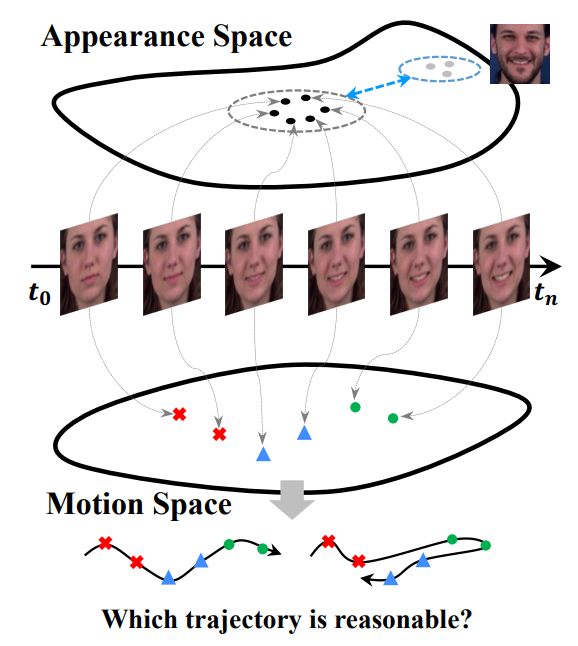
Self-Supervised Video GANs: Learning for Appearance Consistency and Motion Coherency
Sangeek Hyun, Jihwan Kim, Jae-Pil Heo CVPR, 2021 paper Self-supervised approaches with dual discriminators improve video GANs by ensuring appearance consistency and motion coherency through contrastive learning and temporal structure puzzles. |
|
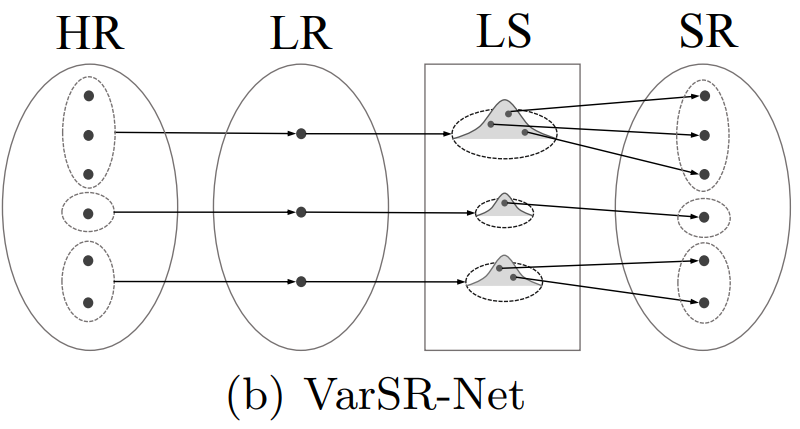
VarSR: Variational Super-Resolution Network for Very Low Resolution Images
Sangeek Hyun, Jae-Pil Heo ECCV, 2020 paper VarSR leverages latent distributions to address the many-to-one nature of single image super-resolution, generating diverse high-resolution images from low-resolution inputs. |
|
|