Scalability has driven recent advances in generative modeling, yet its principles remain underexplored for adversarial learning. We investigate the scalability of Generative Adversarial Networks (GANs) through two design choices that have proven to be effective in other types of generative models: training in a compact Variational Autoencoder latent space and adopting purely transformer-based generators and discriminators. Training in latent space enables efficient computation while preserving perceptual fidelity, and this efficiency pairs naturally with plain transformers, whose performance scales with computational budget. Building on these choices, we analyze failure modes that emerge when naively scaling GANs. Specifically, we find issues as underutilization of early layers in the generator and optimization instability as the network scales. Accordingly, we provide simple and scale-friendly solutions as lightweight intermediate supervision and width-aware learning-rate adjustment. Our experiments show that Generative Adversarial Transformers (GAT), a purely transformer-based and latent-space GANs, can be easily trained reliably across a wide range of capacities (S through XL). Moreover, GAT-XL/2 achieves state-of-the-art single-step, class-conditional generation performance (FID of 2.18) on ImageNet-256 in just 60 epochs, 4× fewer epochs than strong baselines.
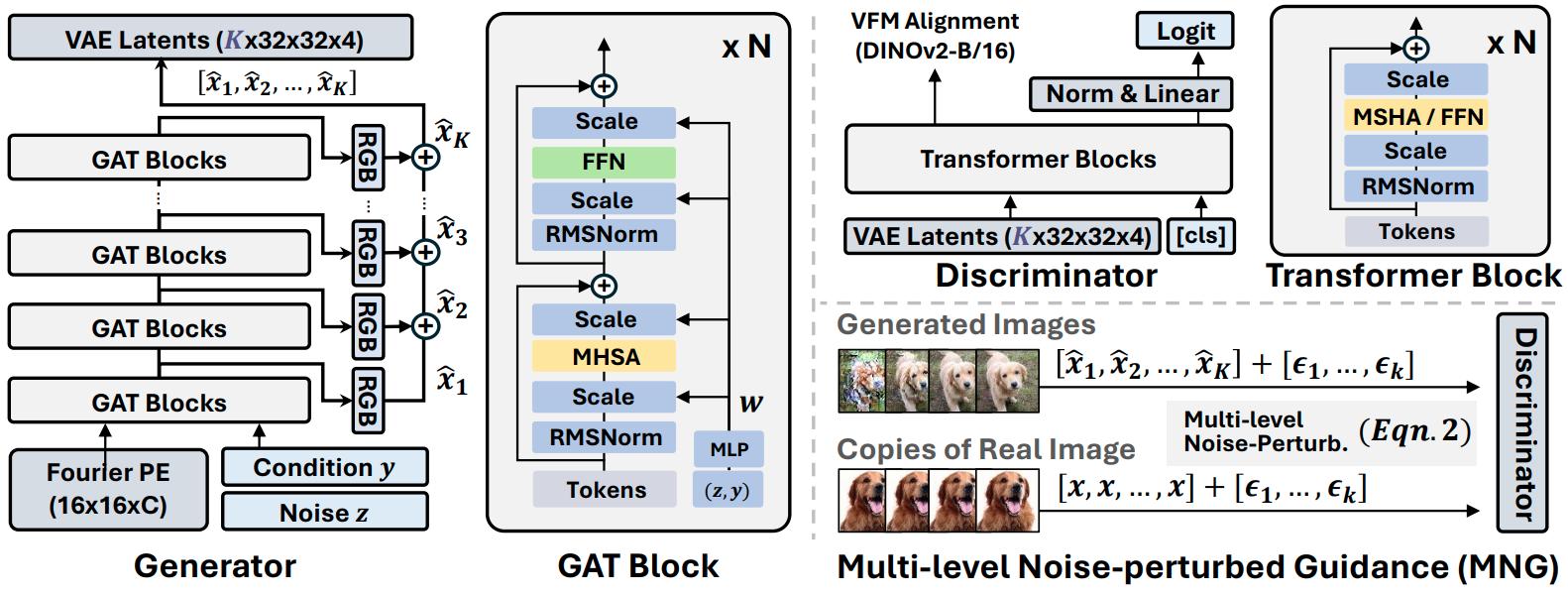
We revisit GANs through the lens of scalability, pairing two proven ingredients of scalable generative models—training in a compact VAE latent space for efficient, high-fidelity computation and pure transformer architectures that scale with width, depth, data, and compute, to build and study a transformer-only latent-space GAN across substantial capacity ranges.
Our analysis surfaces two scale-coupled failure modes (1) early generator layers become inactive, contributing little to synthesis, and (2) naïvely increasing depth/width with fixed hyperparameters accelerates per-step output changes, destabilizing training. To resolve (1), we introduce Multi-level Noise-perturbed image Guidance (MNG), a noise-hierarchical supervision that aligns intermediate generator outputs with progressively less-corrupted real images, restoring early-layer influence and improving layer-wise utilization. To resolve (2), we propose a simple, width-aware scaling rule, especially for the learning rate, that preserves a near-constant magnitude of output change per optimization step, stabilizing adversarial training as models grow.
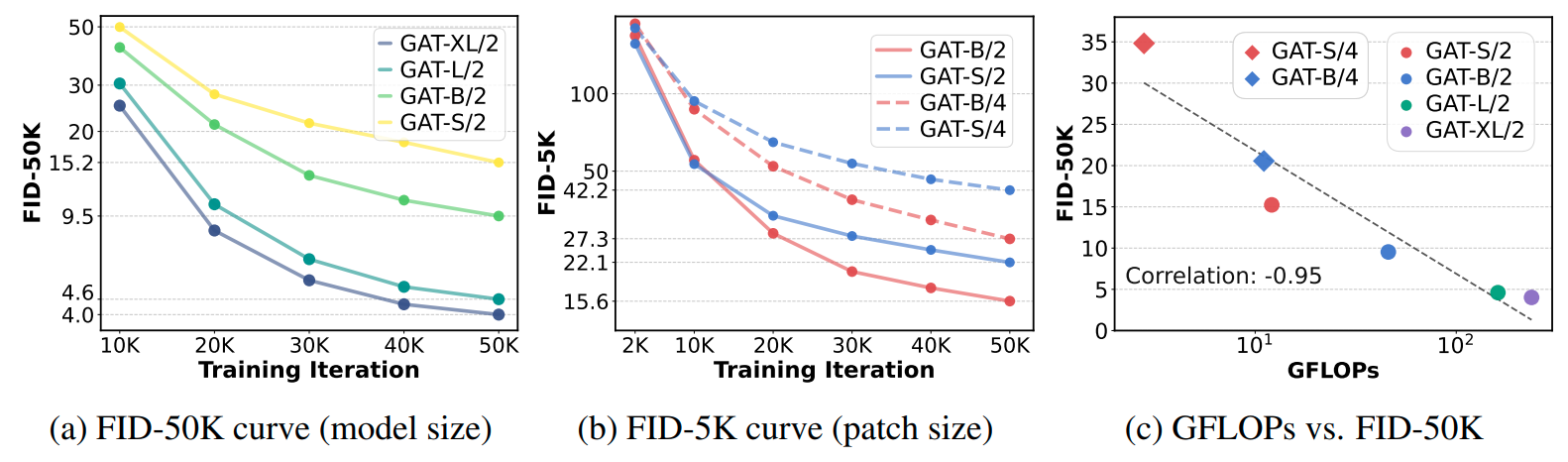
Our experiments demonstrate the scalability of GAT; (a) increasing model size yields consistently better quality throughout training, not just at convergence; (b) training remains robust across tokenization granularity (e.g., larger patch sizes), while larger patch size achieves consistently lower FID; and (c) performance improves systematically with compuitational cost (GFlops), showing the method effectively converts additional capacity into gains. In short, GAT is a scale-friendly framework whose performance rises smoothly with model size, tokenization choices, and computational budget.

Uncurated examples (ImageNet-256, class 89)

Uncurated examples (ImageNet-256, class 279)

Uncurated examples (ImageNet-256, class 207)

Uncurated examples (ImageNet-256, class 387)

Uncurated examples (ImageNet-256, class 933)

Uncurated examples (ImageNet-256, class 817)

Uncurated examples (ImageNet-256, class 417)

Uncurated examples (ImageNet-256, class 979)
We show latent-space interpolations performed in style (w) space. Our pure-Transformer GAN inherits key properties of classic GANs, notably a semantic latent space where continuous moves correspond to coherent changes in content and appearance. As we traverse between different classes and noise seeds, images evolve smoothly. These results indicate that, despite its architectural departure and the space to learn (vae latent), GAT preserves the controllable geometry of GAN latent spaces, enabling image-to-image morphs via simple interpolation in w-space.
For any further questions, please contact hse1032@gmail.com@misc{hyun2025scalableganstransformers,
title={Scalable GANs with Transformers},
author={Sangeek Hyun and MinKyu Lee and Jae-Pil Heo},
year={2025},
eprint={2509.24935},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2509.24935},
}