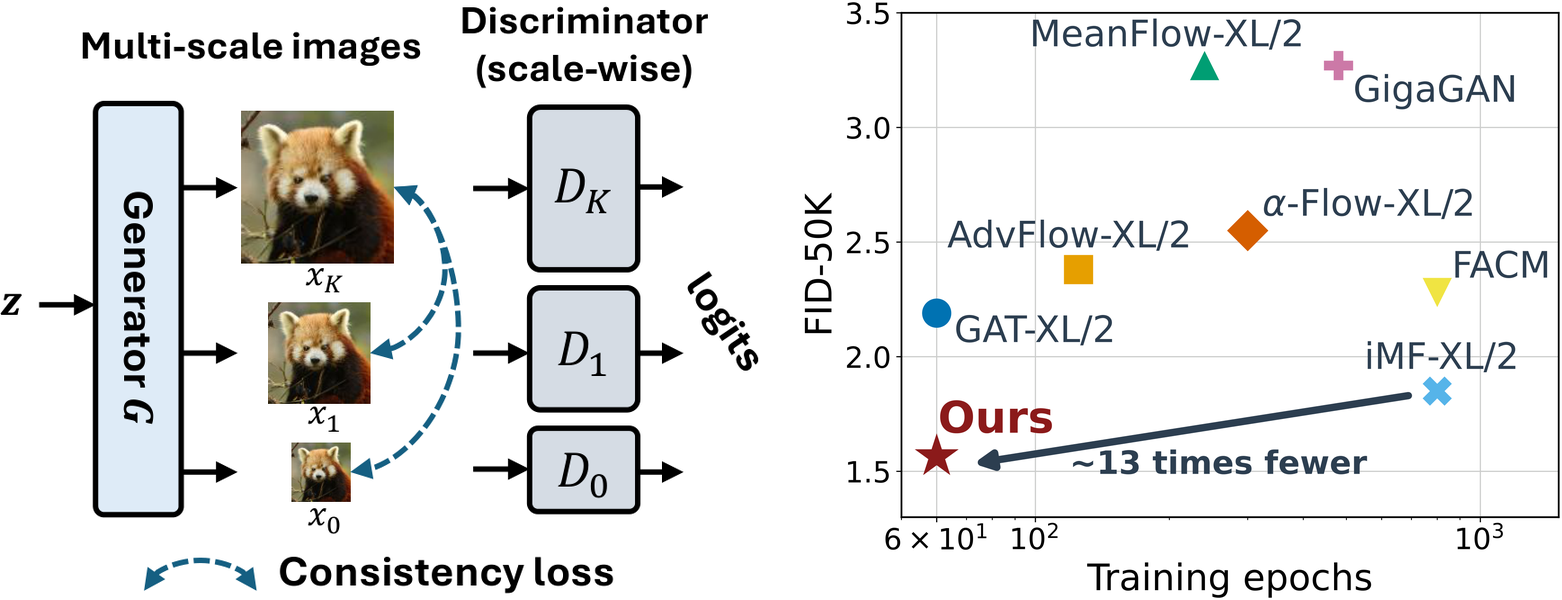
Multi-stage generators naturally produce intermediate outputs, and a common way to train them is to apply adversarial supervision at multiple scales. However, making every intermediate output realistic at its own resolution is not the same as making all stages describe the same generated sample. A low-resolution output can be pushed toward one plausible mode, while later stages may move toward another.
CAT addresses this cross-scale trajectory misalignment. The discriminator remains scale-wise, so each output receives direct adversarial feedback at its own resolution. The generator is then regularized to keep intermediate outputs aligned with the final output, making scale-wise supervision contribute to a shared coarse-to-fine synthesis trajectory.
This simple organization makes Transformer GAN training substantially more effective. On class-conditional ImageNet-256, CAT-H/2 achieves FID-50K 1.56 with a single generator forward pass, while also reducing cross-scale discrepancy, inter-stage rewriting, and misaligned refinement directions.
Scale-wise supervision provides useful local signals, but it does not specify how different stages should coordinate. Each discriminator head only asks whether an image looks realistic at a particular scale. As a result, independently valid gradients can pull different generator stages toward different samples, breaking the intended coarse-to-fine hierarchy.
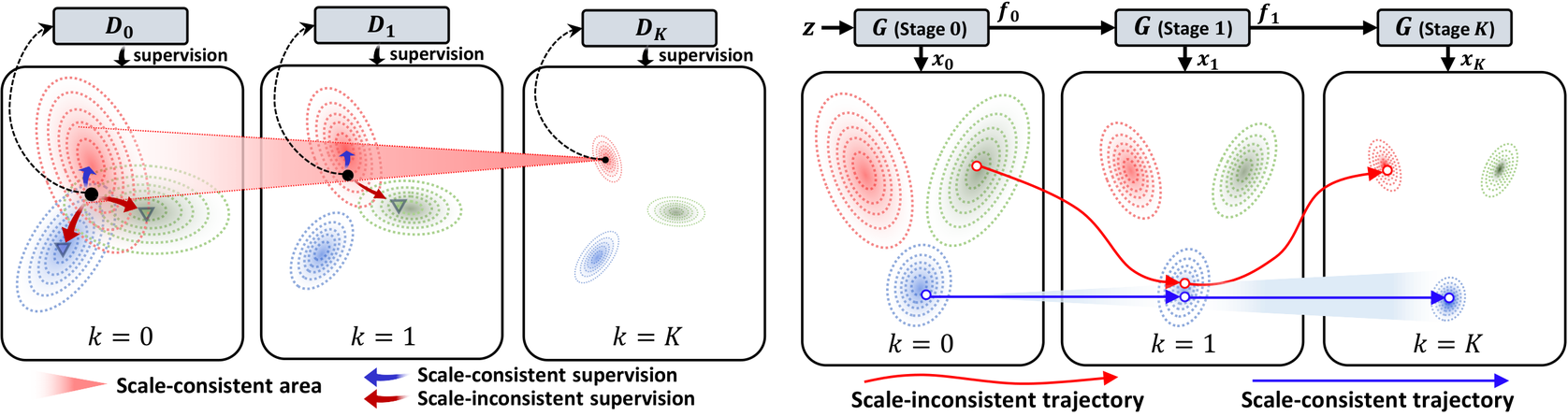
Standard scale-wise supervision can create realistic intermediate outputs without enforcing sample-wise alignment. Later stages may therefore rewrite earlier outputs instead of consistently refining them.
CAT separates two roles that are often entangled in multi-scale GANs. The discriminator is responsible for direct scale-specific realism feedback. The generator-side consistency term is responsible for cross-scale coordination. This keeps the adversarial objective clean while giving the multi-stage generator an explicit alignment target.
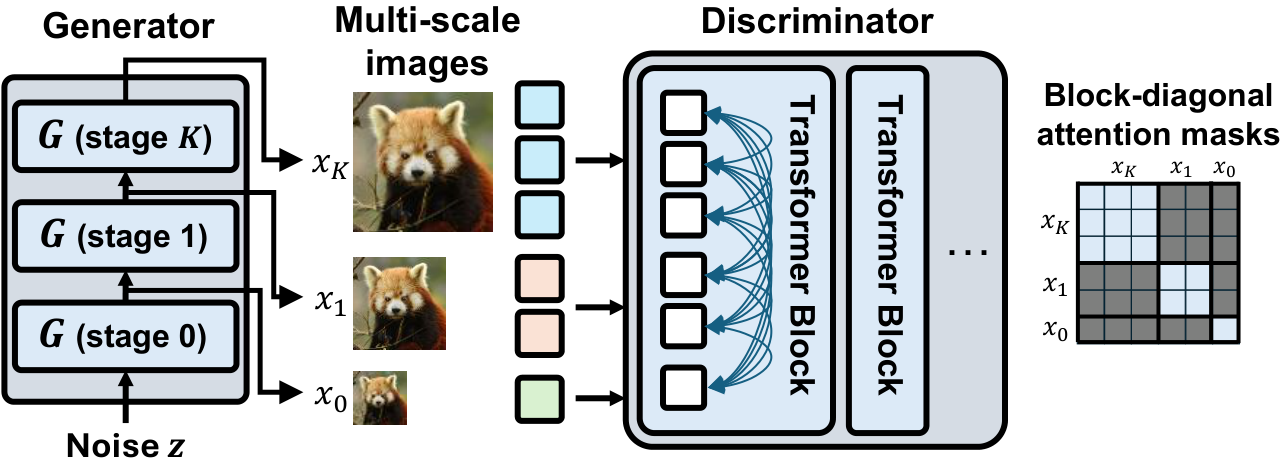
Scale-wise discrimination is implemented by preventing cross-scale token exchange inside the discriminator. Each scale-specific prediction is computed from its corresponding image, while cross-scale alignment is handled on the generator side.
The consistency loss uses the final-stage output as the common anchor. Lower-scale outputs are encouraged to remain compatible with this final image, so their adversarial feedback is more likely to support the same final synthesis rather than a competing trajectory.
CAT is designed around a measurable behavior: intermediate outputs should become progressively aligned with the final output. We evaluate this with three diagnostics: distance to the highest-scale output, inter-stage rewrite magnitude, and rewrite direction alignment.
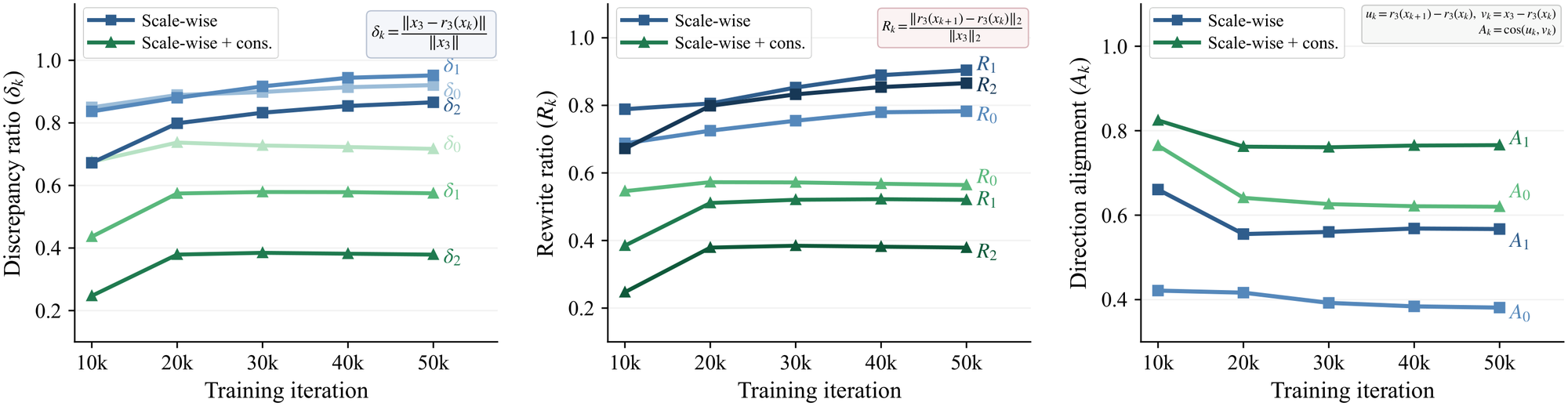
Generator-side consistency reduces the gap between intermediate and final outputs, decreases the amount of rewriting between stages, and makes stage-wise updates better aligned with the remaining direction toward the final image.
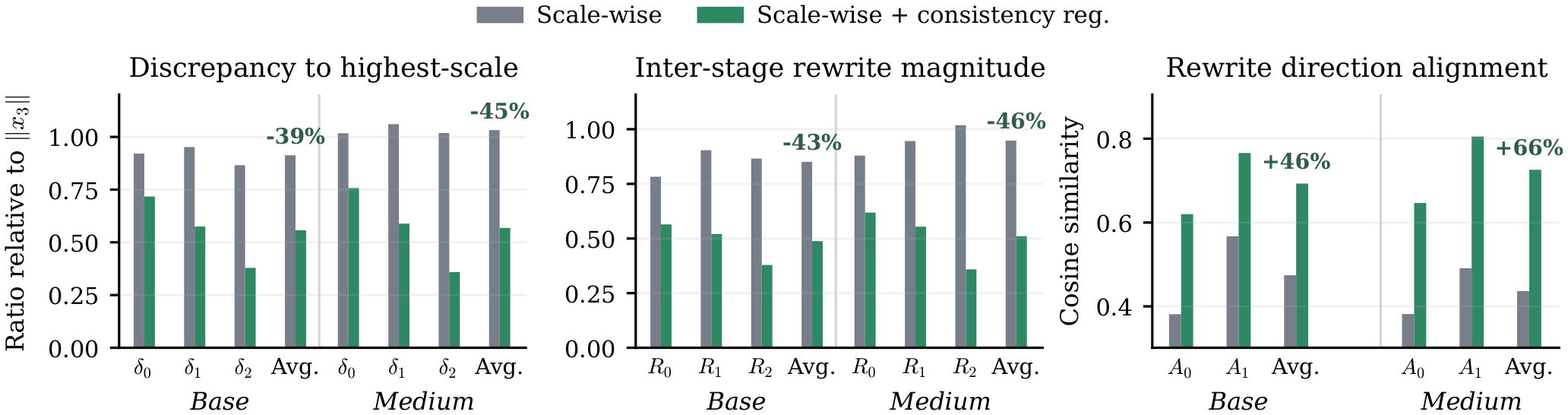
The alignment effect is consistent across model sizes. CAT improves the internal coherence of multi-scale generation, not only the final FID.
A natural alternative is to give the discriminator the entire image pyramid and let it judge cross-scale consistency directly. CAT avoids this design because it can entangle scale-specific adversarial feedback: a discriminator logit for one scale may depend on evidence from other scales, making the learning signal less directly tied to the image being supervised.
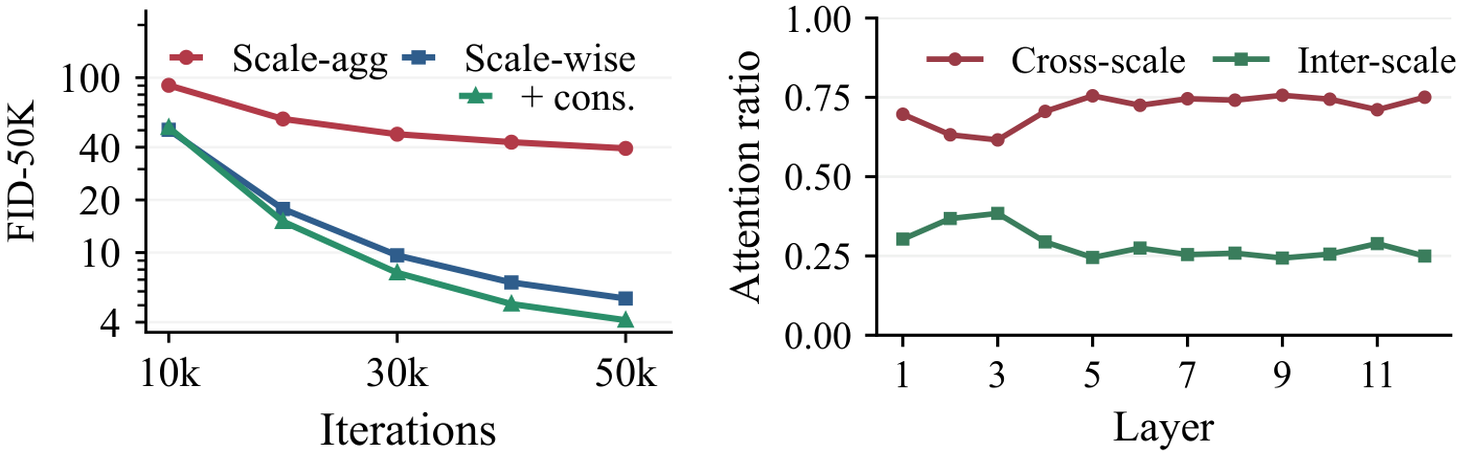
When cross-scale interaction is allowed inside the discriminator, attention becomes strongly coupled across resolutions and performance degrades. This supports the CAT design: keep the discriminator scale-wise and impose cross-scale alignment on the generator.
CAT targets one-step generation. After training, sampling requires only one generator forward pass. The method achieves strong ImageNet-256 FID while using far fewer training epochs than recent one-step diffusion and flow baselines.
| Method | Params | GFLOPs | Epochs | FID-50K |
|---|---|---|---|---|
| 1-NFE diffusion/flow from scratch | ||||
| MeanFlow-XL/2 | 676M | 119 | 240 | 3.43 |
| α-Flow-XL/2 | 676M | 119 | 300 | 2.58 |
| FACM | 675M | 119 | 800 | 2.27 |
| iMF-XL/2 | 610M | 175 | 800 | 1.72 |
| 1-NFE GANs from scratch | ||||
| GigaGAN | 569M | - | 480 | 3.45 |
| AdvFlow-XL/2 | 673M | - | 125 | 2.38 |
| StyleGAN-XL | 166M | 1574 | - | 2.30 |
| GAT-XL/2 | 602M | 119 | 60 | 2.18 |
| CAT-M/2 (Ours) | 261M | 46 | 40 | 1.93 |
| CAT-H/2 (Ours) | 960M | 167 | 60 | 1.56 |
CAT produces diverse ImageNet-256 samples with one-step inference. Latent interpolation also remains smooth, indicating that the improved multi-scale supervision preserves a coherent GAN latent space.

Uncurated generated samples and latent interpolation on ImageNet-256.
For any further questions, please contact hse1032@gmail.com@misc{hyun2026crossscalealignedsupervision,
title={Cross-scale Aligned Supervision for Training GANs},
author={Sangeek Hyun and MinKyu Lee and Jae-Pil Heo},
year={2026},
eprint={2605.26449},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2605.26449},
}